
Introduction
This project aims to use an external USB camera connected to the UNIHIKER to recognize ancient Chinese poetry and display the corresponding author category.
Project Objectives
Learn how to use MultinomialNB model to categorize ancient poems.
Software: Mind+ Programming Software
Practical Process
1. Hardware Setup
Connect the camera to the USB port of UNIHIKER.

Connect the UNIHIKER board to the computer via USB cable.

2. Software Development
Step 1: Open Mind+, and remotely connect to UNIHIKER.

Step 2: Create a new folder named AI in the "Files in UNIHIKER", and then create a new folder named "Ancient Poetry Classification Using MultinomialNB on UNIHIKER", and import the dependency files of this lesson.
Tips: 0-train.py is the program used to train ancient poems and their corresponding authors, you can add datasets to it, model.joblib is the model generated by training, which is used to classify ancient poems, so we can use it directly here.
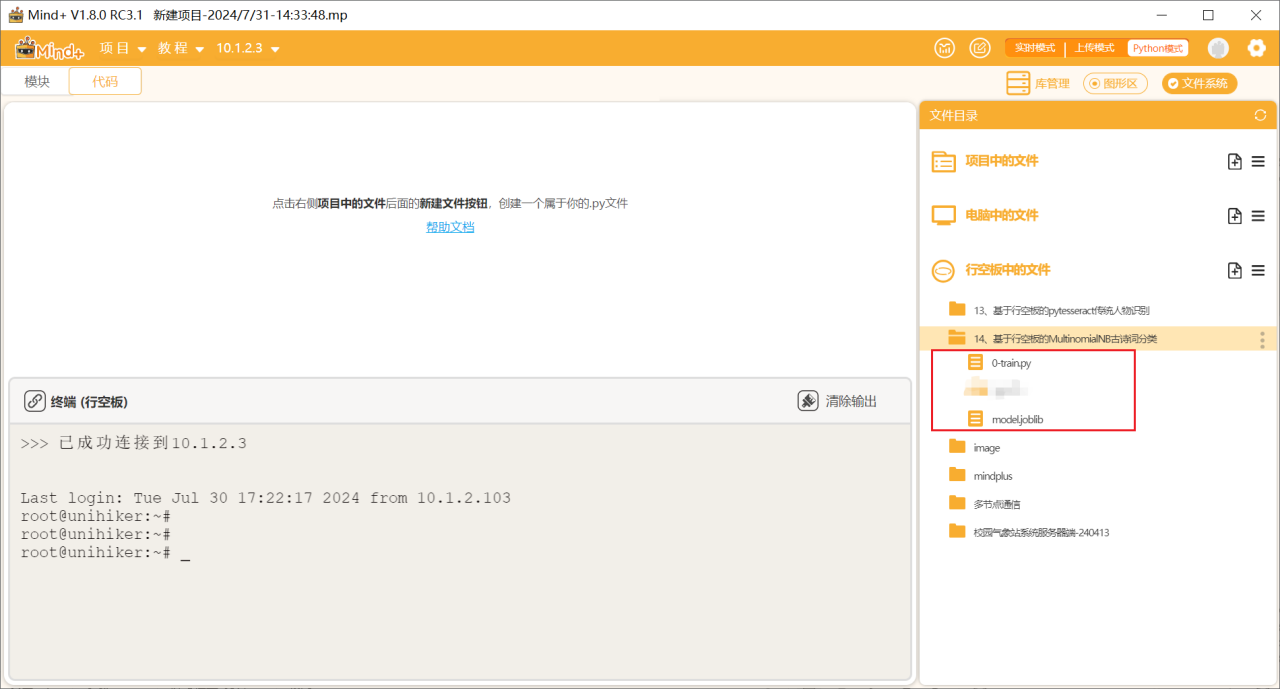
Step3: Create a new project file in the same directory as the above file and name it "main.py".
Sample Program:
# -*- coding: UTF-8 -*-
# MindPlus
# Python
import sys
sys.path.append("/root/mindplus/.lib/thirdExtension/nick-pytesseract-thirdex")
from pinpong.board import Board, Pin
import time
import cv2
import pytesseract
from PIL import Image, ImageFont, ImageDraw
import os
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from joblib import dump, load
model = load('model.joblib')
Board().begin()
def drawChinese(text, x, y, size, r, g, b, a, img):
font = ImageFont.truetype("HYQiHei_50S.ttf", size)
img_pil = Image.fromarray(img)
draw = ImageDraw.Draw(img_pil)
draw.text((x, y), text, font=font, fill=(b, g, r, a))
frame = np.array(img_pil)
return frame
pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 240)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 320)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
cv2.namedWindow('cvwindow', cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('cvwindow', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
while not cap.isOpened():
continue
print("start!")
ShiBieNaRong = ''
img_word1 = ''
img_word2 = ''
while True:
cvimg_success, img_src = cap.read()
cvimg_h, cvimg_w, cvimg_c = img_src.shape
cvimg_w1 = cvimg_h * 240 // 320
cvimg_x1 = (cvimg_w - cvimg_w1) // 2
img_src = img_src[:, cvimg_x1:cvimg_x1 + cvimg_w1]
img_src = cv2.resize(img_src, (240, 320))
cv2.imshow('cvwindow', img_src)
key = cv2.waitKey(5)
if key & 0xFF == ord('b'):
print
break
elif key & 0xFF == ord('a'):
ShiBieNaRong = []
try:
if not os.path.exists("/root/image/pic/"):
print("The folder does not exist, created automatically")
os.system("mkdir -p /root/image/pic/")
except IOError:
print("IOError, created automatically")
break
cv2.imwrite("/root/image/pic/image.png", img_src)
time.sleep(0.2)
img = Image.open('/root/image/pic/image.png')
ShiBieNaRong = pytesseract.image_to_string(img, lang='chi_sim')
print(ShiBieNaRong)
probs = model.predict_proba([ShiBieNaRong])
predicted_index = probs[0].argmax()
predicted_label = model.classes_[predicted_index]
confidence = probs[0][predicted_index]
print(f'Prediction result: {predicted_label}, Confidence: {confidence}')
img_src = drawChinese(text=str(ShiBieNaRong), x=10, y=20, size=25, r=50, g=200, b=0, a=0, img=img_src)
cv2.imshow('cvwindow', img_src)
cap.release()
cv2.destroyAllWindows()
3、Run and debug
Step 1: Run the main program
Run the main.py program to see the initial screen displaying the real-time camera feed. Point the camera at an ancient poem, such as "红掌拨清波" (Red palms stir clear waves), and press 'a' key to capture and save this frame. The text on the image will then be automatically recognized, and the recognized Chinese text and the predicted author will be displayed in the Mind+ software terminal.
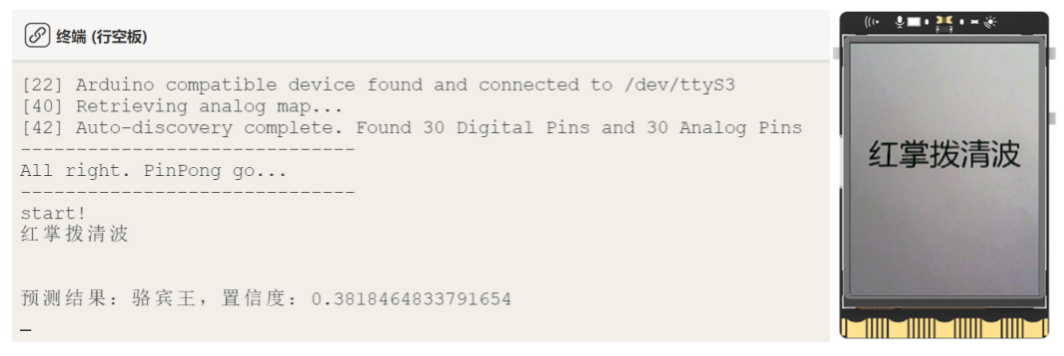
Tips: If the prediction result is not accurate, you can adjust the data set in "0-train.py" to train the model.
4. Program Analysis
This program reads the image from the camera in real time by calling the camera using the OpenCV library, and then uses Tesseract to perform OCR (Optical Character Recognition) recognition and display the result on the image. The recognized text is also classified by a pre-trained MultinomialNB model, and the prediction results and confidence level are displayed. The specific process is as follows:
① Initialization:
- Import the required libraries and modules.
- Initialize the UNIHIKER
- Set the path of Tesseract OCR.
- Turn on the camera and set the resolution and buffer size.
- Create a full-screen window to display the image.
② Define functions:
- Define drawChinese function to draw Chinese characters on the image.
③ Load model:
- Use joblib to load the pre-trained MultinomialNB model.
④ Main loop:
- Enter the infinite loop to read the image from the camera.
- Detect key input:
- press 'b' key, exit the program.
- press ‘a' key, capture the current image and save it to the specified path.
- OCR Recognition using Tesseract to extract text from the image.
- Use the pre-trained MultinomialNB model to predict the classification of the extracted text and output the prediction result and confidence level.
- Draw the recognized text on the image and display the processed image in a window.
⑤ End:
- Release the camera device and close all OpenCV windows.
Knowledge Corner - MultinomialNB Model
MultinomialNB is a machine learning model for text classification and is part of the scikit-learn library. It is an implementation of the Multinomial Naive Bayes classifier. Here is a detailed introduction to MultinomialNB:
Overview
- Definition: MultinomialNB is a type of Naive Bayes classifier specifically for discrete features (usually word counts or term frequencies in text data).- Naive Bayes Model: A simple yet powerful probabilistic classifier based on Bayes' theorem, assuming features are conditionally independent.- Multinomial Model: Suitable for scenarios where features are represented by a multinomial distribution, often used for text classification tasks such as spam detection and document classification.
Features
- Simple and Effective: The model is simple and computationally efficient, suitable for large datasets.- Text Classification: Performs well in natural language processing (NLP) tasks, especially in text classification.- Probability Output: Can output the prediction probability for each class, helping to understand the model's confidence.
Main functions
1.Text Classification:
- Suitable for classifying discrete features, especially word frequency or Bag-of-Words model representation of text data.
- Classification prediction using word frequency statistics and category conditional probability.
2. Multi-category support:
- Supports multi-category classification tasks and can handle multiple categories of classification problems.
Feel free to join our UNIHIKER Discord community! You can engage in more discussions and share your insights!







