
Introduction
This project is to connect an external USB camera on the UNIHIKER and recognize the name of the person through the camera.
Project Objectives
Learn how to use pytesseract library for text recognition.
Software: Mind+ Programming Software
Practical Process
1. Hardware Setup
Connect the camera to the USB port of UNIHIKER.

Connect the UNIHIKER board to the computer via USB cable.

2. Software Development
Step 1: Open Mind+, and remotely connect to UNIHIKER.

Step 2: Find a folder named "AI" in the "Files in UNIHIKER". And create a folder named "Traditional Character Recognition using Pytesseract on UNIHIKER" in this folder. Import the dependency files for this lesson.
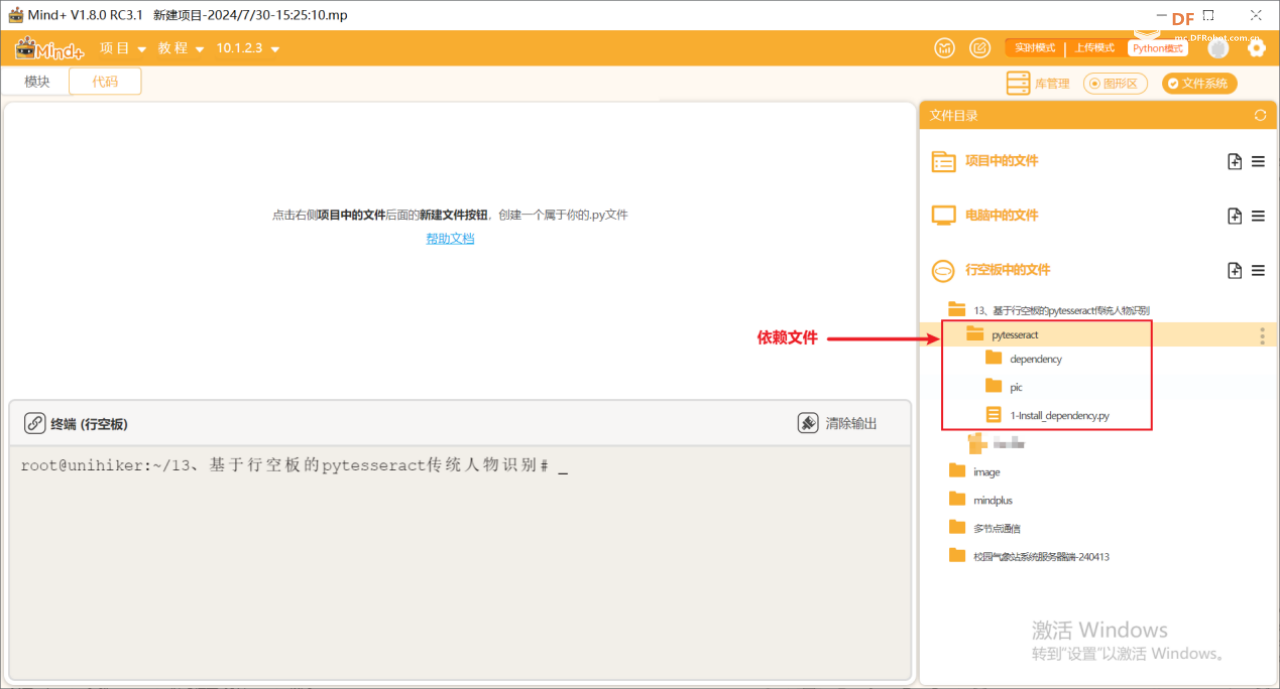
Step3: Create a new project file in the same directory as the above file and name it "main.py".
Sample Program:
# -*- coding: UTF-8 -*-
# MindPlus
# Python
import sys
sys.path.append("/root/mindplus/.lib/thirdExtension/nick-pytesseract-thirdex")
# from pinpong.board import Board
from pinpong.board import Board,Pin
from pinpong.extension.unihiker import *
# from pinpong.libs.dfrobot_speech_synthesis import DFRobot_SpeechSynthesis_I2C
import time
import cv2
import pytesseract
from PIL import Image,ImageFont,ImageDraw
import os
import numpy as np
Board().begin()
# p_gravitysynthesis = DFRobot_SpeechSynthesis_I2C()
# p_gravitysynthesis.begin(p_gravitysynthesis.V2)
def drawChinese(text,x,y,size,r, g, b, a,img):
font = ImageFont.truetype("HYQiHei_50S.ttf", size)
img_pil = Image.fromarray(img)
draw = ImageDraw.Draw(img_pil)
draw.text((x,y), text, font=font, fill=(b, g, r, a))
frame = np.array(img_pil)
return frame
pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 240)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 320)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
cv2.namedWindow('cvwindow',cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('cvwindow', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
while not cap.isOpened():
continue
print("start!")
ShiBieNaRong = ''
img_word1 = ''
img_word2 = ''
while True:
cvimg_success, img_src = cap.read()
cvimg_h, cvimg_w, cvimg_c = img_src.shape
cvimg_w1 = cvimg_h*240//320
cvimg_x1 = (cvimg_w-cvimg_w1)//2
img_src = img_src[:, cvimg_x1:cvimg_x1+cvimg_w1]
img_src = cv2.resize(img_src, (240, 320))
cv2.imshow('cvwindow', img_src)
key = cv2.waitKey(5)
if key & 0xFF == ord('b'): # Press the "a" key on Unihiker will stop the program.
print("Exiting video")
break
# if (button_a.is_pressed()==True):
elif key & 0xFF == ord('a'):
ShiBieNaRong = []
try:
if not os.path.exists("/root/image/pic/"):
print("The folder does not exist,created automatically")
os.system("mkdir -p /root/image/pic/")
except IOError:
print("IOError,created automatically")
break
cv2.imwrite("/root/image/pic/image.png",img_src)
time.sleep(0.2)
img = Image.open('/root/image/pic/image.png')
ShiBieNaRong = pytesseract.image_to_string(img, lang='chi_sim')[0:2]
print(ShiBieNaRong)
img_src = drawChinese(text=str(ShiBieNaRong),x=10, y=20,size=25,r= 50,g=200,b=0,a=0,img=img_src)
cv2.imshow('cvwindow', img_src)
cap.release() # Release usb camera.
cv2.destroyAllWindows() # Destory all windows created by opencv.
3、Run and debug
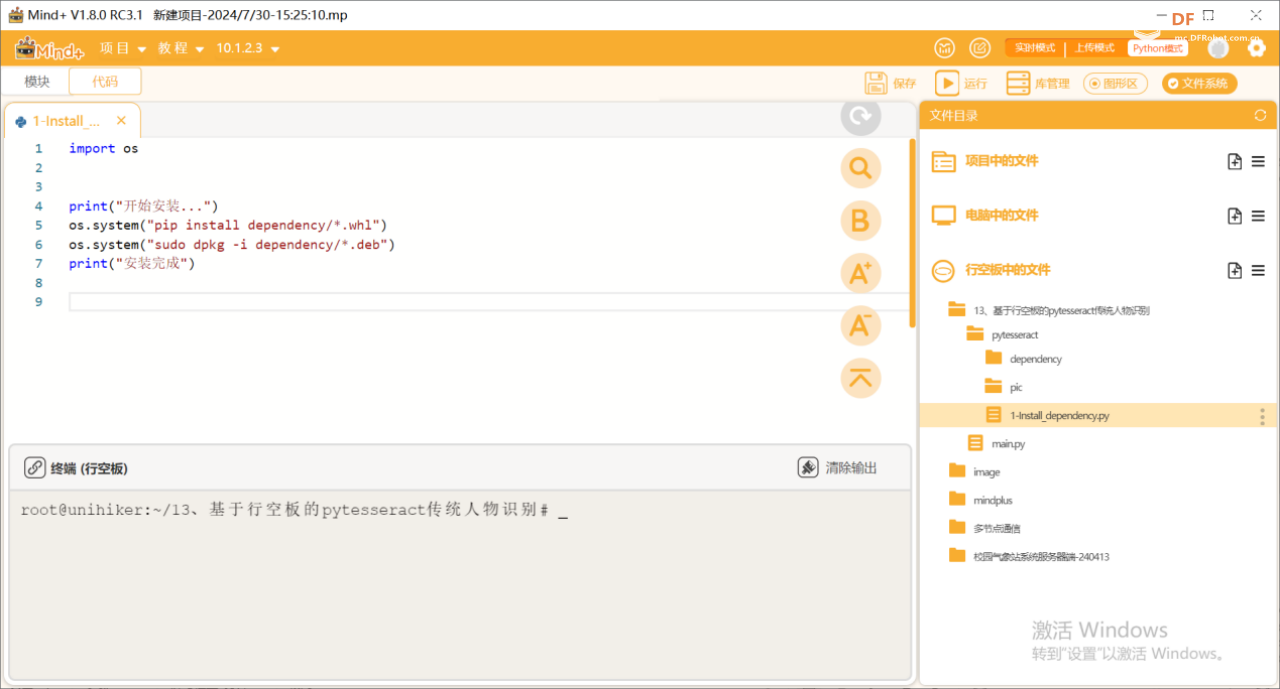
Step 1: Install the dependency libraries
Run the 1-Install_dependency.py program file in the pytesseract directory to install each dependency library.
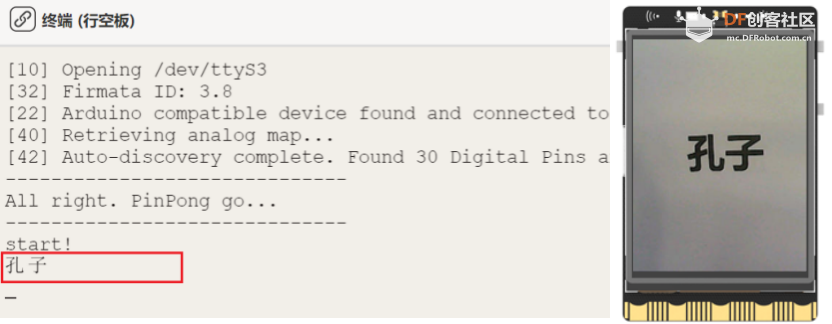
Step 2: Run the main program
Run the "main.py" program, you can see the initial screen shows the real-time image captured by the camera, align the camera frame with the task name, such as here for Confucius, and then press a key, the image will be captured and saved, and then automatically recognize the text on the image, in the Mind+ software terminal, we can see the recognized Chinese results. can see the recognized Chinese result.
Tips: The pictures are saved in the path /root/image/pic.
4. Program Analysis
This program reads the image from the camera in real time by calling the camera using the OpenCV library, and then uses Tesseract to perform OCR recognition and display the result on the image. The specific process is as follows:
① Initialization: When the program starts, it imports the required libraries, initializes the UNIHIKER, configures the Tesseract command path, opens the default camera device, and sets the camera resolution and buffer size. Next, a full-screen window is created for displaying the image.
② Define function: Define a function drawChinese for drawing Chinese characters on the image.
③ Main loop: the program enters an infinite loop, in each loop, the program performs the following operations:
- Read a frame from the camera. If the reading fails, the program continues to the next loop.
- Check for key events:
- If key 'b' is pressed, the program exits the loop.
- If key 'a' is pressed, the program captures the current image and saves it to the specified path, then uses Tesseract to recognize the Chinese characters in the image and prints the result to the terminal.
- Draw the recognized Chinese characters on the image and display the processed image in the window.
④ End: When the main loop ends, the program releases the camera device and closes all OpenCV windows.
Knowledge Corner - pytesseract library
Pytesseract is a Python wrapper library for the Tesseract OCR engine for extracting text from images. It provides easy interfaces that make it easy to implement Optical Character Recognition (OCR) in Python programs.
Features
1. image text recognition: extract text from various image formats (such as PNG, JPEG, BMP, etc.).
2. multi-language support: able to recognize text in multiple languages .
3. Layout Analysis: Handles complex document layouts, including multi-column text and tables.
4. location information extraction: provide the location coordinates of recognized characters or words in the image.
5. multiple output formats: supports plain text, dictionary format, HOCR (HTML OCR) format, and so on.
Features
1. open source and free: based on the open source Tesseract OCR engine, free to use.
2. cross-platform: support for Windows, macOS and Linux systems .
3. high accuracy: Tesseract engine after years of development and optimization, with high recognition accuracy.
4. easy to integrate: provides a simple Python interface, easy to integrate with other Python projects and libraries.







